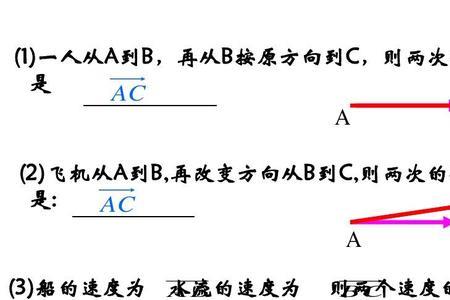
我们先了解一下向量检索,计算机情报检索的一种重要方式。
检索系统中的每一个记录(文献表示或数据条目)用一个由若干标引词的权值构成的向量来表示,称为文献向量。
通过计算文献向量之间的相似度生成聚类文档,作为检索的基础。用户的问题(信息需求)也用同样的方法表示,称为提问向量。
检索作业(即提问向量与文献向量的匹配操作)在系统的聚类文档中进行。先计算给定提问向量与文献(类)向量之间的相似度,然后使相似度超过某一阈值(或者根据预定要检出的文献数量)的文献按相似度大小降序排列输出。
采用此方式的检索系统实现了局部匹配策略和排序输出技术,提高了检索的灵活性和效率。
它还可以采用相关反馈技术来自动优化提问向量,或者采用动态文献向量调整技术来优化聚类文档的结构,进一步改善检索效果。基于上述原理建立的系统模型称为向量空间模型。此模型以假定标引词之间相互独立(即具有正交性)为前提,故存在一定的理论缺陷。